
第一周
1-2-2
递归的空间复杂度很大:

而循环通常只对一块内存反复使用。
计算机计算乘除法会比加减法慢很多。所以乘法越多,时间复杂度越大。
1-2-3
Ω表示复杂度上界
O表示复杂度下界
Θ表示上下界一致
具体如下:

第二周
课后练习 一元多项式的乘法与加法运算
函数题:02-线性结构1 两个有序链表序列的合并

裁判测试程序样例:
1 |
|

分析题目
题目的关键:直接使用原序列中的结点。
代码
1 | List Merge(List L1,List L2){ |
(1)可以用来代替
1 | if(t1) |
用来挂上剩余的链表。
(2)题目要求在原来的链表上操作,因此完成后需要把L1和L2设置为空链表。
第三周 树(上)
树的问题本质上是通过递归的方式简化为“根左右”的方式来处理。
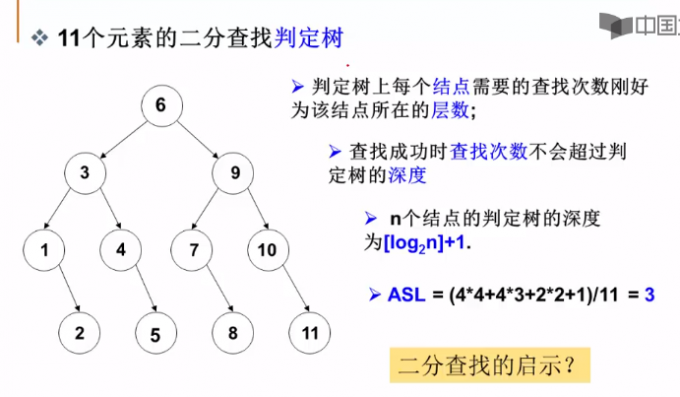
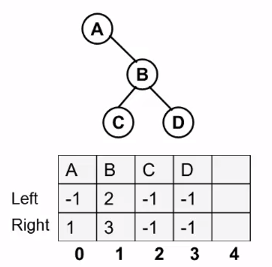
一棵树想用顺序存储结构来表示显然是不方便的,因此我们通常用链式存储结构来表示。
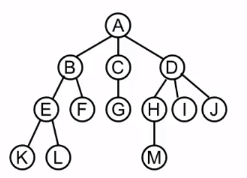
对于这棵树,优先能想到的链式表示方法如下:
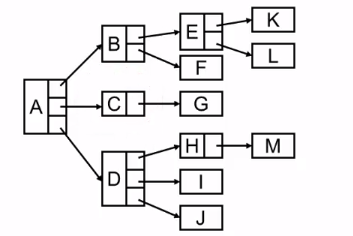
这种方法有个缺陷,需要定义多种不同类型的结构体,非常不方便。如果我们把所有结点设计成度最大的结构,对于指针域又是一种极大浪费,因此就引入了孩子兄弟表示法。如图所示:
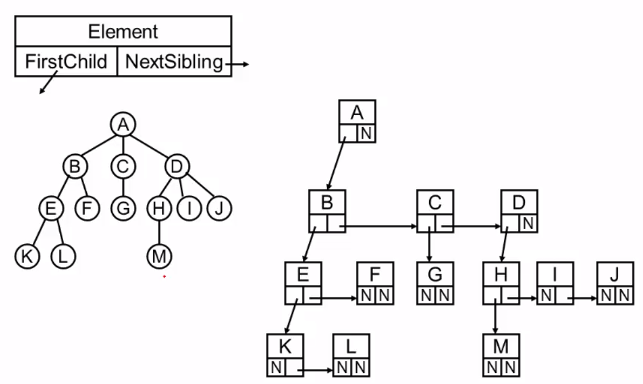
这样只会浪费n+1个指针域,也统一了结点的样式,而右边这个样式,就是二叉树。
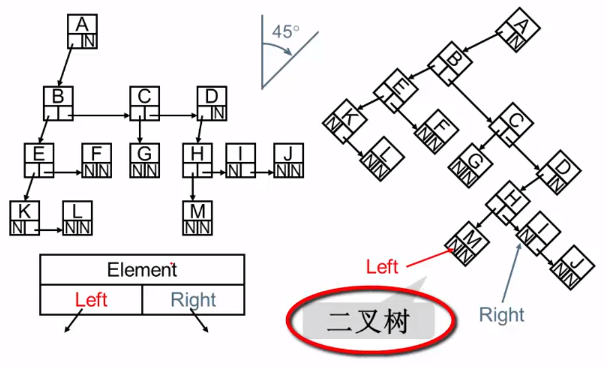
二叉树
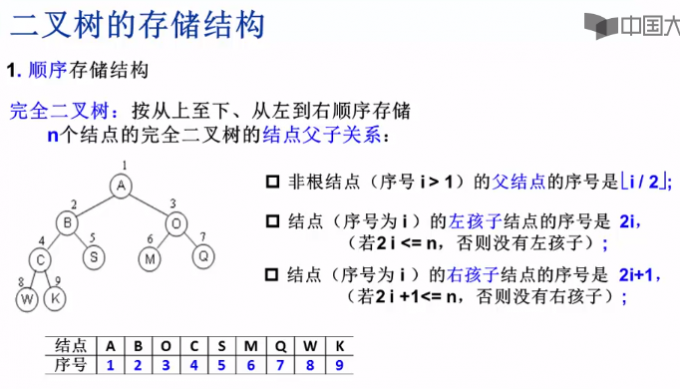
二叉树是可以进行顺序存储的
完全二叉树很适合顺序存储
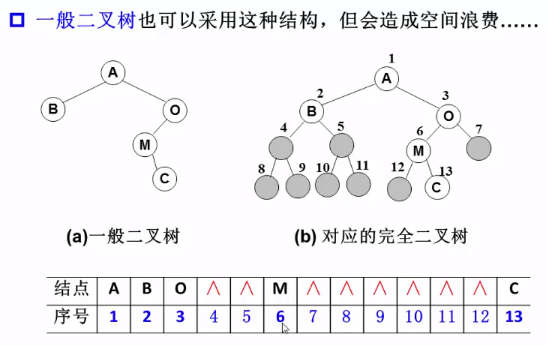
非完全二叉树也可以顺序存储,只要将其补成完全二叉树即可,但会浪费很多空间:
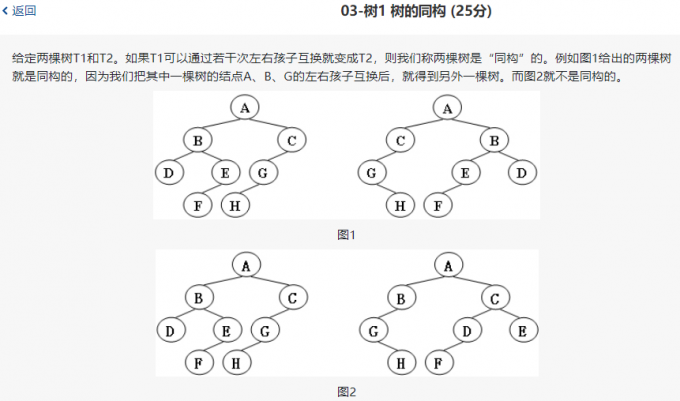
03-树1 树的同构

1 |
|
(0)用静态链表来做这题,即下面例子中的存储格式:
(1)scanf()中如果带有\n,那么只有当它遭遇到下一个非空格字符时才会执行。
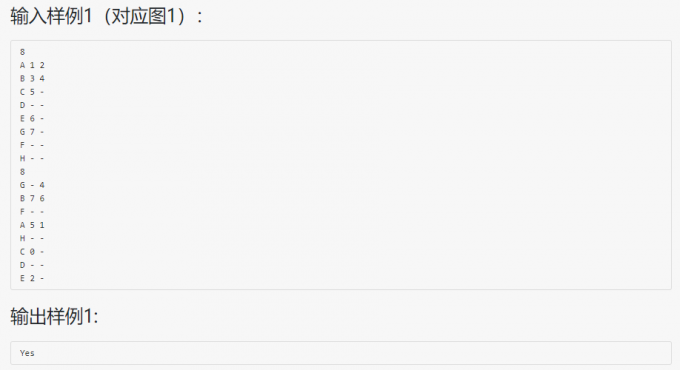
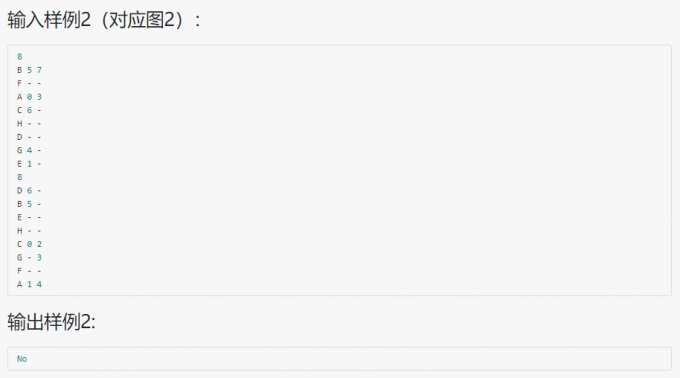
03-树2 List Leaves
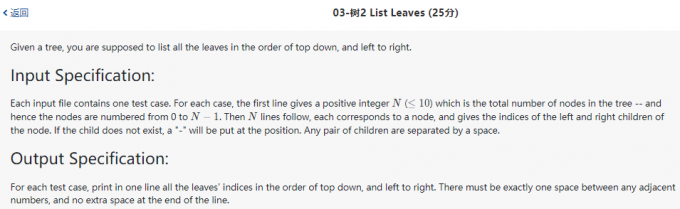
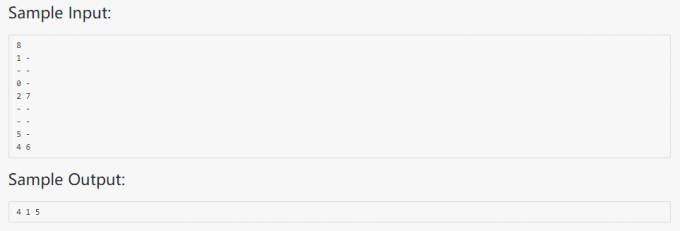
代码:
1 |
|
(1)层序遍历需要用到队列,为了方便我直接用了顺序存储的队列。
(2)一般来说,结构体变量可以用另一个变量对其进行赋值和初始化,但是成员中含有指针时上面的情况就无法实现。
第四周 树(中)
二叉搜索树
查找分为静态查找和动态查找(查找过程中需要插入,删除等操作)。我们知道二分查找可以提高查找效率,是因为其查找过程可以建立为一棵树,因此我们不如直接将数据的形式按照树的方式存储,这样还可以进行动态查找,这棵树就叫二叉搜索树。
如何建立一棵二叉搜索树:
1 | TreeNode makeTree(int n){ |
关于建树的一些小tip:
(1) 先建立根节点,再读入,这样才能把根节点记录下来
(2)建树的过程大致为:先建立节点,再插入树中。
04-树4 是否同一棵二叉搜索树 (25分)

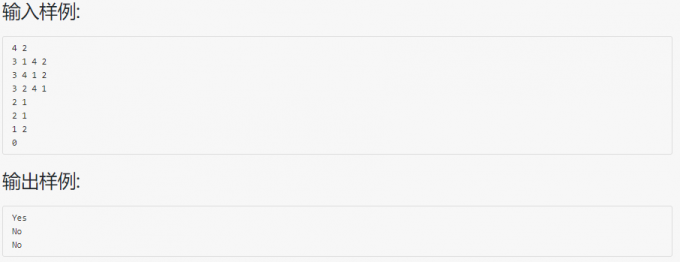
代码:
1 |
|
04-树5 Root of AVL Tree (25分)
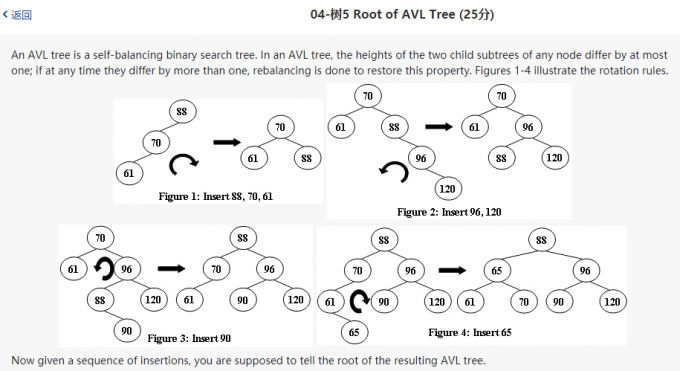
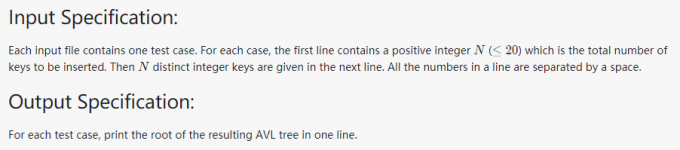
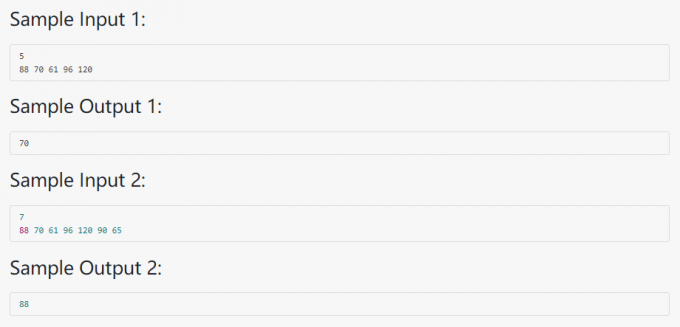
代码:
1 |
|
AVL树的关键:
1、判断失衡的类型(LL、RR、LR、RL)
插入新结点后,找到失衡结点,从失衡结点开始到新结点的路径中数3个结点,他们所构成的就是失衡类型(需要调整的结点并不一定包括新插入结点)
2、LL、RR、LR、RL调整方法
见注释
第五周 树(下)
堆(heap)
如果我们需要一个队列,按照优先级而不是FIFO的形式出队,有下面几种构造方法:

我们发现无论使用那种结构,时间复杂度都为O(n),但如果使用二叉树的方法,可以大大降低时间复杂度。这种二叉树结构称之为“堆”。
在二叉搜索树中,我们知道搜索树的时间复杂度和树的高度有关,因此我们可以用完全二叉树来保持堆的左右子树的平衡,而为了方便删除最大优先级(或最小,以下都以最大为例)结点,我们把优先级最大的结点记为根结点。
因此,堆的两个条件:
- 完全二叉树
- 任一子树,其根结点优先级都大于其所有孩子结点
因此自顶向下沿着任一路径,结点优先级都是从大到小,我们称为大顶堆(根节点优先级最小,称为小顶堆)。
堆的插入与删除
以最大堆为例,树中元素顺序存储。
插入
完全二叉树在最后插入元素,同自己的父结点比较,若大于父节点,则和父节点交换。
删除
删除堆的根节点元素,用最后一个元素代替,然后与左右孩子结点比较,将其中值最大的移动到根节点。
05-树7 堆中的路径

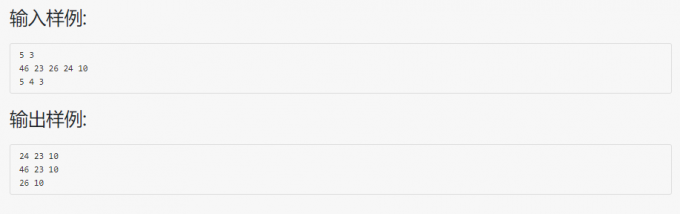
代码:
1 |
|
官方参考代码:
插入结点(建堆):

05-树8 File Transfer

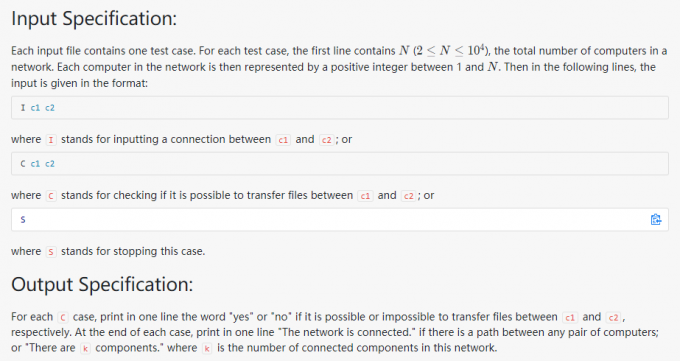
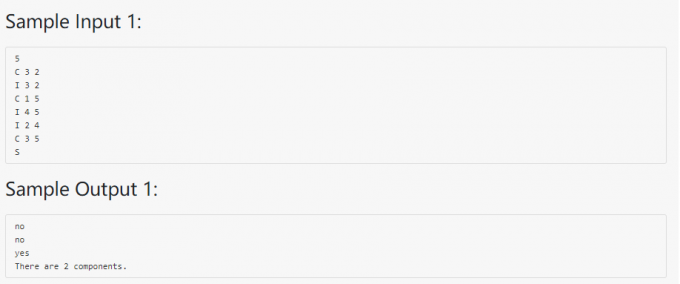
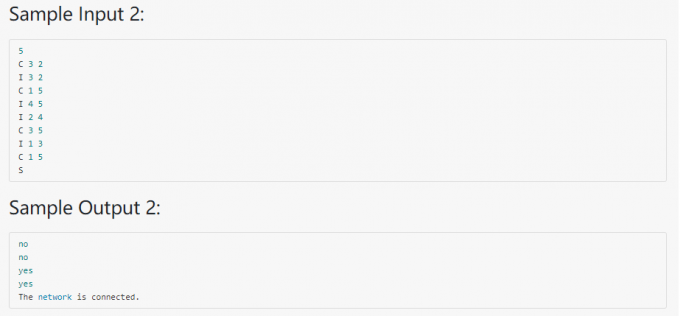
代码:
1 |
|
测试结果:

之所以会运行超时,原因在于,原代码中
1 | void Union(SetType S[],ElementType root1,ElementType root2){ |
极端情况下会导致树高不断增加,出现下面的情况:
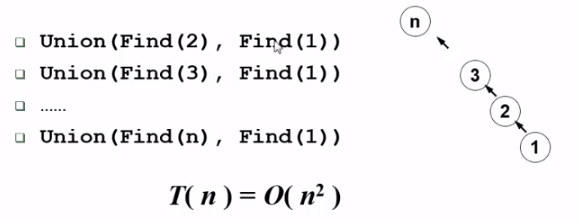
解决方法有两种
按秩归并
- 按树高归并
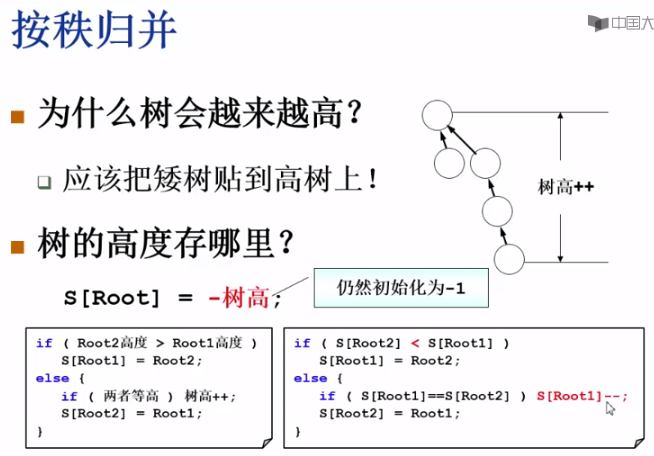
按规模归并

路径压缩
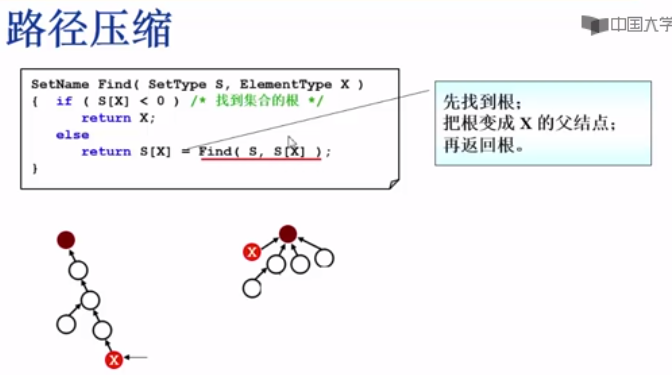
最后采用路径压缩:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
typedef int Setname;
typedef int ElementType;
typedef ElementType SetType;/*定义一个elementType数组类型*/
void initializeUFS(SetType S[],int N);
void checkUnion(SetType S[]);
ElementType Find(SetType S[],ElementType node);
void inputUnion(SetType S[]);
void Union(SetType S[],ElementType root1,ElementType root2);
void searchUnion(SetType S[],int N);
int main(){
int N=0;
char in;
scanf("%d",&N);
SetType S[N];
//初始化
initializeUFS(S,N);
do{
scanf("%c",&in);
switch(in){
//检查
case 'C':
checkUnion(S);
break;
//连接
case 'I':
inputUnion(S);
break;
//相连的机器
case 'S':
searchUnion(S,N);
break;
}
}while(in!='S');
}
void initializeUFS(SetType S[],int N){
for(int i=0;i<N;i++){
S[i]=-1;
}
}
void checkUnion(SetType S[]){
int a=0,b=0;
ElementType root1=0,root2=0;
scanf("%d%d",&a,&b);
//找到两台机器根结点
root1=Find(S,a-1);/*下标要-1*/
root2=Find(S,b-1);
if(root1==root2)
printf("yes\n");
else
printf("no\n");
}
ElementType Find(SetType S[],ElementType node){
/* 一般方法
1
\
2
\
3
for(;S[node]>=0;node=S[node])
;
return node;
*/
/* 路径压缩
1
/ \
2 3
*/
if(S[node]<0)
return node;
else
return S[node]=Find(S,S[node]);
}
void inputUnion(SetType S[]){
Setname a=0,b=0;
ElementType root1=0,root2=0;
scanf("%d%d",&a,&b);
root1=Find(S,a-1);
root2=Find(S,b-1);
if(root1!=root2)
Union(S,root1,root2);
}
void Union(SetType S[],ElementType root1,ElementType root2){
/* 把root1挂在root2下面 */
S[root1]=root2;
}
void searchUnion(SetType S[],int N){
ElementType count=0;
for(int i=0;i<N;i++){
if(S[i]==-1) count++;
}
if(count==1)
printf("The network is connected.\n");
else
printf("There are %d components.\n",count);
}
第六周 图(上)

6.2图的遍历
深度优先搜索(deepth search first,DFS)
类似于先序遍历(递归,所以用到的是系统堆栈)
广度优先搜索(breath search first,BFS)
类似于层次遍历(需要用到辅助queue)
06-图1 列出连通集(25分)
visited数组不要设置为DFS函数的局部变量

